データマイニング予測の仕組み
JRA-VAN では、皆様の馬券購入の参考になるように、データマイニング予測として、レース結果を事前に予測しています。
世の中には、気象予測、経済予測、株価予測など、さまざまな予測がコンピュータにより行われています。競馬の世界でも、スピード指数、レーティング指数などさまざまな数式や指数が、勝敗予測のために用いられていますが、それらの中のひとつがJRA-VANのデータマイニング予測です。
2008年1月以降予測の仕組みについて以下の改修を行っております。本文では改修後の仕組みについてご説明します。
- 予測モデルの細分化
- 2008年1月から距離別レースクラス別に予測モデルを分割
- 2009年1月から上記に2歳戦・3歳戦に限定した予測モデルを追加
- 従来の走破速度予測モデルに加え、競走馬の勝敗を予測するモデルを追加
- 予測のためのデータとして坂路調教データを追加
- 予測モデルの更新タイミングの短縮
- データマイニングツールの変更
2010年4月より、競走馬の勝敗を予測するモデルの運用を開始いたしました。詳しくはこちらを参照ください。
オマケのコラム
1.基本となる考え方
(1) 競馬は予測可能な現象であると仮定する
競馬は、競走馬と人間(騎手、調教師等)が、その能力をフルに使って速さを競うレースです。速く走る素質を持った馬が、優秀な調教師によってその素質にさらに磨きをかけられ、レース当日に上手な騎手が馬の能力をフルに引き出そうとすることによって、レースの勝敗は決まります。
レース当日の馬の速さに関係していると思われるデータを事前に入手し、それらをうまく組み合わせることにより、ある程度の予測が可能な現象である、といえます。データから結果が予測可能である、という意味では、天気予報や企業の倒産予測などと同じと言えるでしょう。
Aさんが明日の夕食に何を食べるか、というような人間の意志のみによって結果が左右される事項、あるいは、宝くじやサイコロのように結果が全く偶然によって決まる事項とは異なるのです。
もちろん、あくまで予測ですから結果を 100 %正しく予測することは不可能です。なぜ完全な予測はできないのでしょうか?理由はいくつか考えられますが、
- 騎手の体調や心理状態、同様に馬の体調や心理状態、調教の仕上がり具合など、レース結果を左右する要因が非常に多く、そのデータのすべてを事前に入手することが不可能である。
- 各馬を個別に評価して比較する方法、他馬との駆け引きや展開を読む方法など、データから結果を予測する方法が無限にあり、完全な方法が見つからない。
- 騎手や馬の置かれた状況に、必然的に偶然性が入り込む。
などがその理由でしょう。
しかし、現実的な範囲でできるだけ多くのデータを集め、それらを吟味しうまく組み合わせることによって、予測の精度を上げる可能性が高まります。そして膨大な量の各種データを処理して予測するためには、コンピュータを利用することが必要となってきます。
(2) 客観的なデータのみを使用する
予測では、JRA発表の公式データのみを使用しています。これには、前走タイム、父馬名などの客観的なデータのみが含まれています。また、なるべくデータの質を均一に、かつ、誤差を少なくするために、前レースの成績や騎手の勝率などの計測可能な値は相対的な値に変換しています。
また、レース前に発表されるオッズも予測には使用していません。オッズは、競馬ファンの様々な予想や人気が集大成された結果であり、ある意味では予測に近いデータであるという見方もできます。
しかし、よく考えてみると、オッズが馬の着順や走破タイムに影響を及ぼすとは思えません。オッズはあくまで人気をあらわす指標であり、レースの勝敗に影響を与える要因ではない、という考え方からオッズは予測には使用していません。
(3) 馬の速度を予測する
競馬の予測には様々な方法があります。また、何を予測するのかについても、着順/走破タイム/走破速度など、いろいろあります。
JRA-VANの予測モデルでは、データマイニングや統計の処理上扱いやすい、走破速度を予測しています。ただ、予測速度のみを数値で表示すると、直感的にわかりにくい数字となるため、レースの距離と予測速度から予測走破タイムを算出して表示しています。
2.予測モデルの説明
使用している予測モデルの内容、作成経緯等についてご説明します。
(1) モデルの概要
データマイニングによる予測モデルにはいくつかのタイプがありますが、現在運用している予測モデルはニューラルネットワーク(BPN)を利用しています。
2010年4月より、2種類の予測モデルを運用しております。
- 走破速度を予測するモデル(以降、走破タイム型モデル)
- 競走馬の勝敗を予測するモデル(以降、対戦型モデル)
走破タイム型モデルは、従来通りのモデルであり、過去のレース成績データから算出した各競走馬の走破速度を教師データとし、競走馬の属性、騎手、調教師、レース情報などから、次回レースの走破速度を予測するもので、走破速度と距離からタイム換算してJRA-VAN NEXTのマイニング画面で表示しています。一方、対戦型モデルは、過去のレースにおいて、対戦実績のある競走馬同士の勝ち負けを教師データとし、競走馬の属性、騎手、調教師、レース情報などから、次回レースで対戦する競走馬の勝ち負けを予測するもので、各競走馬の強さを100点補正して、JRA-VAN NEXTのマイニング画面で表示しています。
走破タイム予測モデルでは、主に出走馬単独のデータを使用して走破タイムを予測していたのに対して、対戦型モデルでは、出走馬2頭のデータを使用して2頭間の相対差(今回は順位に基づく勝ち・負け)を学習させている点が大きく異なります。出馬表に並んだ出走馬の属性や過去成績等を2頭ずつ比較してどちらが強いのかを予測し、最終的にレース全体で相対的に最も強い競走馬を探し出すといったプロセスをコンピュータに行わせています。
以降は、従来通りのモデル、走破タイム型の予測モデルについて、モデルの概要を説明いたします。
走破タイム型の予測モデルは、2008年1月時点では、芝について距離別 4区分×レースクラス 3区分の 12個、ダートについて距離 3区分×レースクラス 3区分の 9個、障害 1個の合計 22個のモデルで運用していましたが、2009年1月には、新たに2歳戦と3歳戦に限定したモデル(以降、2歳・3歳モデル)を追加しました。2歳・3歳モデルを追加することとなった理由は、走破タイム型の予測モデルは、過去走の影響を受けやすい特性を持っており、比較的経験の少ない2歳・3歳馬の予測を適切行うためにはリーディングなどの競走馬の属性情報を重視したモデルが必要と判断したためです。2歳・3歳モデルの詳細は、こちらでご確認いただけます。
以下の表は現在運用しているモデル区分を表します。新馬・未勝利戦レースクラスは、2歳・3歳モデルを適用し、芝中・長距離の1勝クラス・2勝クラス(2歳・3歳)については、対象レースが少ないため1つの区分にまとめています。詳細は、以下の通りです。
※ここでの距離の区分は、一般に言われている距離区分と若干異なるかも知れません。
| 距離 | レースクラス | 予測モデル数 | |
|---|---|---|---|
| 芝 | 超短距離(1200m以下) |
新馬・未勝利戦 |
15個 |
| ダート | 短距離(1200m以下) |
新馬・未勝利戦 |
12個 |
| 障害 | 全て | 全て | 1個 |
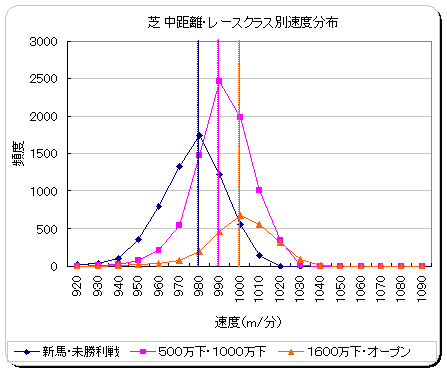
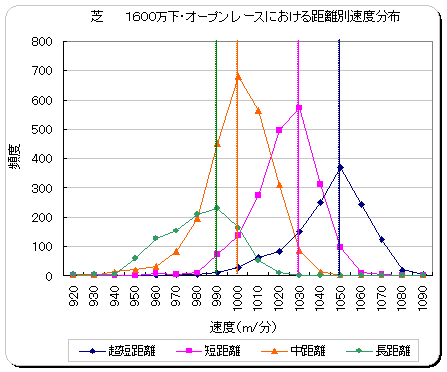
走破速度と距離・レースクラスとの関係は、距離が長いほど、またレースクラスが下位クラス(新馬・未勝利)ほど走破速度が遅くなる関係があります。以下に2000 年〜2005 年における、走破速度と距離・レースクラスの関係性を表した例(グラフ)を示します。ピーク位置の件数に差がでるのは、該当する区分の開催レース数に差があるためです。
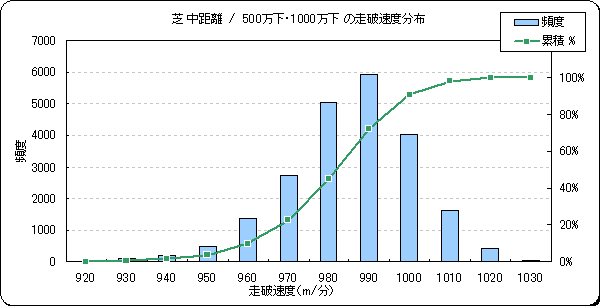
今回採用した予測モデルは、成績データのレース距離と走破タイムから走破速度を求め、走破速度を予測する方法を採用していますが、開発段階では走破速度を対象として次のような試行錯誤を行っています。いずれの方法も走破速度を予測するケースと比較して予測精度に大きな差が現れず、大幅改善が見込めなかったため走破速度を予測する方法のままとしました。参考に、それぞれの予測対象について「芝中距離/1勝クラス・2勝クラス」モデルのデータ分布を示します。
- 走破速度(※今回採用した予測モデルにおける予測対象)
- 試行錯誤1: 走破速度の精緻化
- 走破タイムの記録密度が 0.1秒単位であるため、同じ走破速度でも順位が異なるケースがあります。このケースは走破速度にわずかに差をつけて競走馬間に差があることを学習させることを狙ったものでした。
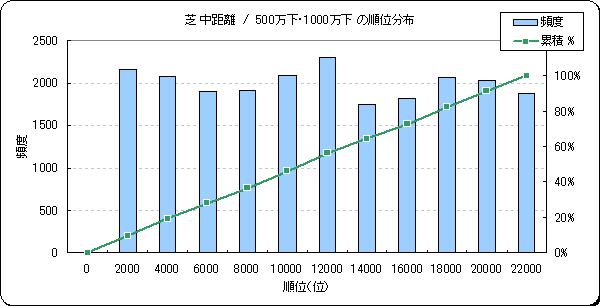
- 試行錯誤2:走破速度の順位付け
- 使用する学習データ全体での予測速度の順位です。走破速度が僅差でもレースの順位として差があるため、走破速度に順位付けを行い(速度順位)差を明確に学習させることが狙いでした。速度順位のデータ分布は走破速度の分布とは異なり、フラットな分布となります。予測精度は走破速度を学習させたケースと大差なかったので、ニューラルネット(BPN)ではこのようなフラットな分布のデータでも学習できることが解りました。
- 試行錯誤3: 基準速度からの偏差
- 上位着馬の走破速度から場、コース、距離等別の基準となる走破速度(基準速度)を求め、基準速度と実際の走破速度の偏差を計算し学習させました。走破速度を学習させたケースでは、場や距離などは速度に大きく影響を与えるためレース単位で同じ予測速度となることがありますが、この方法により競走馬個別のデータを中心に学習させるのが狙いでした。
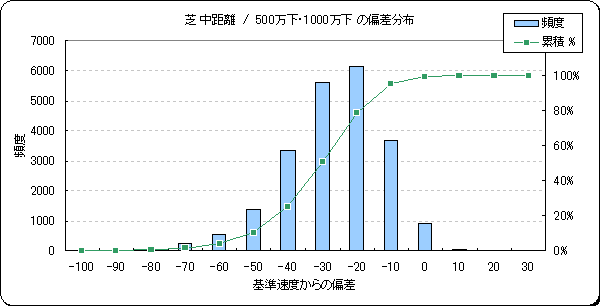
また、今回、距離・レースクラス別にモデルを作成するにあたり、試行段階では、競馬場・グレード・重量種別・馬場、といったレース情報が走破速度に与える影響度を調べました。結果から競馬場別のモデル作成する案もありましたが、予測モデル作成に必要な最低限のデータ件数を確保するため、前述のような距離とレースクラスによるモデル区分を採用しました。
(2) 使用したデータ項目
モデル作成に使用したデータは、以下の通りです。
| 対象レース情報 | |
|---|---|
| 競馬場 | 競馬場の特性を学習する要素として使用 |
| 距離 | 距離が他の因子やタイムとのどのような因果関係があるのかを学習させる |
| コース区分 | 同じ競馬場・同じ距離でも内コース・外コース・直線では走はタイムが大きく異なるため、それらを学習する要素として使用 |
| レース条件(グレード) | レースの格が他の因子やタイムとのどのような因果関係があるのかを学習させる |
| 重量種別 | レース負担重量が他の因子やタイムとのどのような因果関係があるのかを学習させる |
| 天候 | 天候が他の因子やタイムとのどのような因果関係があるのかを学習させる |
| 馬場状態 | 馬場状態が他の因子やタイムとのどのような因果関係があるのかを学習させる |
| 出走メンバー情報 | |
| 出走頭数 | 出走頭数が他の因子やタイムとのどのような因果関係があるのかを学習させる |
| 逃げ馬・先行馬の割合 | 逃げ先行馬が出走頭数に占める割合を利用し、レースのペースとの因果関係を学習させる |
| 予測対象馬 今回情報 | |
| 枠番 | レースコースとの因果関係を学習させるために使用 |
| 馬体重 | 馬体重が他の因子やタイムとのどのような因果関係があるのかを学習させる |
| 馬体重増減割合 | 一日あたりの増減差を計算して入力し、年齢やその他の項目との因果関係を導き、学習させる |
| 負担重量 | 負担重量がタイムに与える影響を学習させる |
| 負担重量率 | 負担重量は馬体重と因果関係があることは既知の事実なので、関連性を外側でつけてから因子として利用する |
| 騎手 勝率 | 騎手の直近100レースの勝率が結果に与える影響を学習させる |
| 騎手 3着内率 | 騎手の直近100レースの3着内率が結果に与える影響を学習させる |
| 予測対象馬 背景情報 | |
| 性別 | 性別が他の因子やタイムとのどのような因果関係があるのかを学習させる |
| 馬齢 | 年齢が他の因子やタイムとのどのような因果関係があるのかを学習させる |
| 調教師 勝率 | 調教師の直近100レースの勝率が結果に与える影響を学習させる |
| 調教師 3着内率 | 調教師の直近100レースの3着内率が結果に与える影響を学習させる |
| 生産者 | 生産者の特性を学習する要素として使用 |
| 馬主 | 馬主の特性を学習する要素として使用 |
| 父 | 父馬の特性を学習する要素として使用 |
| 母父 | 母父馬の特性を学習する要素として使用 |
| 予測対象馬 過去走実績 | |
| 出走回数 | 競走馬の経験値として使用 |
| 1着回数 | 競走馬の経験値として使用 |
| 3着内回数 | 競走馬の経験値として使用 |
| 出走回数(同トラック) | 競走馬の経験値として使用 |
| 1着回数(同トラック) | 競走馬の経験値として使用 |
| 3着内着回数(同トラック) | 競走馬の経験値として使用 |
| 出走回数(同距離) | 競走馬の経験値として使用 |
| 1着回数(同距離) | 競走馬の経験値として使用 |
| 3着内着回数(同距離) | 競走馬の経験値として使用 |
| 重賞出走回数 | 競走馬の経験値として使用 |
| 重賞勝利数 | 競走馬の経験値として使用 |
| 重賞3着内回数 | 競走馬の経験値として使用 |
| 脚質(逃げ・先行) | これまでのレースで逃げもしくは先行した割合。馬の脚質として使用 |
| 前走のレース条件 | 競走馬の格を代用する要素として使用 |
| 前走からの間隔 | ローテーションを示す要素として使用 |
| 前走のレースのレベル | 前走の情報として使用 |
| 前走のレースタイム比 | 前走のレース平均タイム/自身のタイム 前走での該当競走馬の実績として使用 |
| 前走の上がりタイム比 | 前走の上がり平均レースタイム/自身の上がりタイム 前走での該当競走馬の実績として使用 |
| 前2走のレースのレベル | 前走と同様 |
| 前2走のレースタイム比 | 前走と同様 |
| 前2走の上がりタイム比 | 前走と同様 |
| 前3走のレースのレベル | 前走と同様 |
| 前3走のレースタイム比 | 前走と同様 |
| 前3走の上がりタイム比 | 前走と同様 |
| 直近1年のベストタイム比 | 該当競走馬のベストパフォーマンスを示す要素として使用 |
| 直近1年のベスト上がりタイム比 | 該当競走馬のベストパフォーマンスを示す要素として使用 |
| 予測対象馬 坂路調教実績 | |
| 過去1ヶ月の平均調教本数 | 調教の実績を示す要素として使用 |
| 過去1ヶ月の最高ラップタイム | 該当競走馬のベストパフォーマンスを示す要素として使用 |
| 目的変数 | |
| 走破速度 | 該当競走馬の対象レースでの走破速度 |
これらのデータについて、以下のような加工を行いました。加工後のデータと走破速度の関係をニューラルネット(BPN)を使用して学習させ予測モデルを作成します。
- 1.中央競馬成績データの抽出
- 2.データのクレンジング
- 異常値成績(極端に速い/遅い/データなし、などを除去)
- 異常レース(スタート後に競走中止、落馬、降着等があったケース)の場合、対象馬だけでなく同時に走った他馬の成績にも影響があった可能性があるため、そのレース全体に関するデータを除去
- 3.カテゴリデータの処理
- 父馬、母父馬、生産者、馬主など、カテゴリー区分値が多数あるものについては、データ中の出現頻度順の上位はそのまま使用し、残りは1区分に一括しました。
- 4.集計/比率化処理
- 元データのうち、そのまま使用するものもあれば、様々な集計処理や、比率を計算して、その値を入力値として使用したものもあります。
例えば、予測するためには競走馬、騎手、調教師等がそれぞれどの程度の能力を持っているのかを表すデータが必要となります。競走馬の前走の着順、騎手の勝率、調教師の勝率などが考えられますが、予測モデルで走破速度を予測対象としているように、過去成績の評価にも主に走破速度を使用しました。しかし、競馬場、コース、距離等で走破速度が大きく異なっており走破速度そのままでは過去成績を評価できません。そこで、過去に出走したレースの条件を加味した上で過去成績を評価するために、競馬場、コース、距離等により走破速度の基準値を設定し基準値に対する比率を計算することで全ての過去成績を同列に評価できるようにしています。この基準値の求め方についても様々な方法があり、今までの開発のなかで試行・評価を行っています。以下はその一例です。
- 過去の同条件のレースでの上位着馬の走破速度平均値を基準とする。
- ニューラルネット(BPN)で基準値を求める。
(3) 作成経緯
- データマイニングによる競馬予測の作業は、2001年3月よりスタートしました。
- 当初は、レース毎(例えば日本ダービーのモデル)、あるいはレース開催場/コース毎にモデルを作成することも試行しましたが、モデル作成に必要なデータ件数が十分でなく汎用性に乏しい、などの理由から、2007年までは7種類のモデルとし、データマイニングツールとして、日本アイ・ビー・エム(株)の「DB2 Intelligent Miner V6.1」「DB2 Intelligent Miner Scoring」を使用していました。
- 2008 年の改修により、より正確に予測を行うために予測モデルの区分を22個へ増やし、予測に使用するデータとして坂路調教データを追加しました。データの分析/予測モデルの作成は、データマイニングツール「 CSMD (Credit Scoring Model Developer) 」を競馬予測向けにカスタマイズしたものを使用し、JRAシステムサービス(株)の方針のもと(株)ライトウェルが実施しました。
(4) 予測性能の検証例
- モデルで使用している項目の影響度
ニューラルネットワークで予測モデルを作成する場合、できあがったモデルに対して入力データ項目毎の影響度を求めるのは、非線形モデルであるために容易ではなく、線形多変量解析のような一意に決まる寄与率という概念がありません。
しかし、入力データを変動させてそれによる予測値(出力データ)の変動を調査すれば、項目ごとの影響度をある程度知ることができます。これは、出来上がったモデルの「まともさ」を評価する上で非常に重要な作業です。
項目ごとの影響度の大小を比較した場合に、それが常識外れの(競馬ファンの一般的な経験則とあまりにもかけ離れている)場合は、モデルの予測精度がいくら良くても、その理由を調査し、場合によってはモデルを作り直す必要があるといえます。
今回作成したモデルのうち、芝・中距離/1勝クラス・2勝クラス用モデルに対して上記の方法で走破速度に対する影響度を調査した結果は、以下です(影響度の高い上位10位を掲載)。
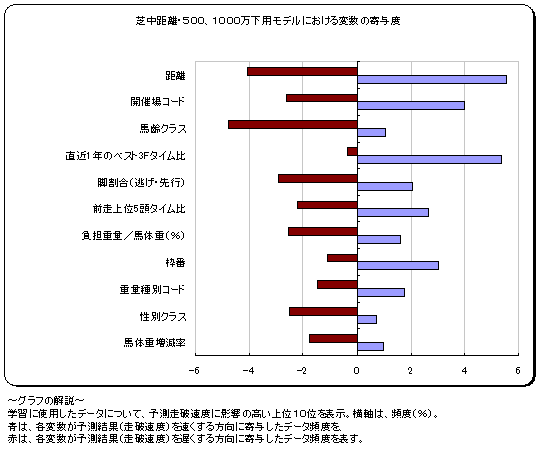
この結果を見ると、レース情報(距離、レース場、重量種別など)や競走馬情報(馬齢、負担重量、枠番など)、前走までの走りっぷり(自身の直近 1年の上がり3Fのベストラップタイムが基準値に対してどれだけ速かったか)などの項目が影響度の上位となっており、競馬常識とさほど矛盾していないようです。
この結果からは、このモデルはある程度「まともな」モデルであるという結論になります。
- 検証用データによる性能検証
- 2001年〜2006年の成績データでモデルを作成し、これで 2007年〜 2008年 6月までのレースを予測し、実績データと比較した結果はこちらです。
(5) 予測モデルの更新
刻々と変化するレース傾向を予測するためには、最新のデータをモデルに取り込むことは必要不可欠です。
従来、モデルの再学習は数年に1度の頻度で行っていましたが、2008年より、予測モデルに開催日前週までの成績データを反映させています。
予測モデルの作成にはおよそ 6年間のデータを使用しており、毎週、1週間のデータの入れ替えが発生します。直近の1週、2週程度では予測精度に差はあらわれませんが、
半年、1年と経過するにつれ予測精度が低下していく傾向にありますので、これを防止する効果が期待できます。
予測モデルが同じ状態で 1年経過した場合の的中率を、予測に使用する過去走成績等のデータが欠損状態となること少ない1勝クラス以上のレースで比較した結果はこちらです。
※現在2010年4月時点では、再学習を行っているのは、走破タイム型モデルのみです。
(6) 今後の課題
予測精度の更なる向上/サービス向上を目指して、引き続き以下の作業を随時行っていく予定です。ご期待ください。
- 予測に使用するデータ、予測モデルの区分等の研究による予測精度の向上
3.予測画面の更新タイミング
予測画面の更新タイミングは以下の通りです。
- 1.対象レースの出馬表が発表された直後(通常金曜日または土曜日)
- 2.対象レース開催日の朝(当日朝時点での天候、馬場状態等を加味した予測)
- 3.対象レース発走時刻の約1時間前(馬体重等を加味した予測)
※不測の事態等によりデータが更新されない、あるいは誤ったデータが表示される可能性があることをご了解の上お使いください。
4.画面表示のみかた
- マイニング画面の左側には、馬番順に予測タイム、予測順位、現在の単勝人気順位が表示されています。
- 右側のゴールイメージ表示では、予測タイムを元に各馬のゴール時のイメージを表示しています。左側のゴールライン(赤い線)に近いほど、予測タイムが速いことをあらわします。
- 馬のイメージの前後に黄色や青色の帯が表示されている場合があります。これは、データの中で不明のもの(例、外国人騎手の戦績、過去走が少ない馬の過去走成績)があった場合に、表示されます。この帯の長さは、不明データのためにタイムの変動が起こりうる可能性の範囲を示しています。
5.馬券購入のヒント
一般的には、予測タイムを参考にしてください。馬連の場合、1着予測馬と、その他の馬の予測タイムの差が大きければ、1着予測馬を軸に流しで購入、差が少なければボックスで購入、などが考えられます。
また、予測着順と人気順の差が大きい場合は、予測着順に黄色または青色で表示されますので、買い方をご検討ください。
いずれにしても、オッズをにらみながら、最適な買い方を皆様ご自身で見つけてください。